
In this article, I will demonstrate the nonsense of using Deep Learning, a neural network, to recognize images using the example of handwriting recognition from the MNIST character set and prove it in practice.
I will also show that to recognize handwritten numbers or a wider picture, it is not necessary to teach the system with tens of thousands of samples, and one or at most several samples will be enough, and it will not matter what size the sample used to teach the system is, or what sample is used to test its effectiveness. Also, it will not matter what the centring, size, angle of rotation or the thickness of written lines are, which is of paramount importance in machine learning or deep learning image recognition methods.
As we know, each image in a computer is made up of single points (Max Planck says, our whole world is made up of pixels), which when connected in an appropriate way create an image. The same is true of the characters that form digits in the MNIST character database.


The MNIST character set and its classification is a kind of abecaddress for every beginner student or person starting to play with deep learning or neural networks.
This collection was compiled by Yann Lecun (http://yann.lecun.com/exdb/mnist/) and contains 70,000 images with a resolution of 28x28 pixels in 255 shades of grey. It is assumed that 60,000 objects are the training set and 10,000 are elements from the test set. The image (in this case the number from 0 to 9) is represented as a 2D matrix of 28x28 pixels with 0-255 pixel grayscale. An easier form to process by machine learning algorithms is the vector form, which is obtained by reading the pixel values from the image line by line. From here we get a 784-dimensional vector (28*28=784) representing one image with a digit. From this it follows that the whole training set is a 60000×784 matrix.
Now all you have to do is use the TensorFlow tools available in the cloud, download a few files in Python, read about many wise ways of teaching the network, buy a few books about it, or just download a ready-made what most do and create your first neural network.
Wow, to one character consisting of 28 lines of 28 points each, specially prepared for recognition, that is, properly centered, calibrated in perfect resolution, the big heads came up with the idea that if our human brain consisting of neurons can read it, we will create a mini electronic brain from artificial neurons, he will also read it. And it worked! The results are almost perfect, close to 100%, but...
Using neural networks to recognize numbers is like replacing a stick for writing numbers on the beach sand with a specialized robot picking one grain of sand from the beach to get the same pattern!
Do you think that our brain looking at a number cuts it into strips, pixels, vectors and analyses it point by point? If we take Dr. Clark's calculation that the resolution of our eyesight is 576 megapixels (not really more than 20 megapixels at the center of the gaze), then there is really no such energy drink that will help our brain in such a job.
What's more, is this what teaching is about? Do we have to see 60,000 characters to learn them, or did the primary school teacher write it once and make us remember it?
If she draws you a certain sign once, for example:

will you recognize the one below as different?

Of course it is a bit different, but if we have a certain set of digits and this sign next to it - then each sign will recognize it even though it is the first time it is seen. He will also have no problems with drawing it after a while in another place.
And now, most importantly, how do we remember this sign? Pixel by pixel, 784 points? And what if it is a 256 by 256 point mark, which is the same as a regular icon on our home computer consisting of 65536 points?
No, our brain is great when it comes to simplifying all the data that comes to it, and even more so when it comes to how much data is as huge as the image data.
Let's think for a moment how we would describe this sign in words to someone else, and we'll get one of the simplified memorization methods - we'll probably describe it more or less like this:
two segments, horizontal and vertical, the first segment is horizontal, and at the end of it, it meets the vertical segment at 90 degrees. Let's note that in this case practically 4 information is enough to describe the sign, not information about 784 points in 255 shades of grey. What is more, the information written this way is independent of the size of the sign.
Exactly the same method can be used to remember every sign, digit, but also the object in the image regardless of whether the object will be in 2D or 3D space (in a nutshell, because recognizing the image in 2D or even 3D space requires additional actions - if you are interested, I will gladly describe some easy recognition methods in the next article).
So once again, what is this simple method?
We will remember:
1. "starting points"
2. "starting angle"
3. "episode type"
4. the "angle of bending of the section"
5. the 'angle of the joint of the section'.
As you can see, I think the human brain remembers the basic shapes and the way they are connected.
We easily detect straight lines, circles, arches more or less bent and their mutual position or connection.
Let's see the number 6 as an example (I also recommend to see everything on the attached video https://youtu.be/do9PM2PtW0M):
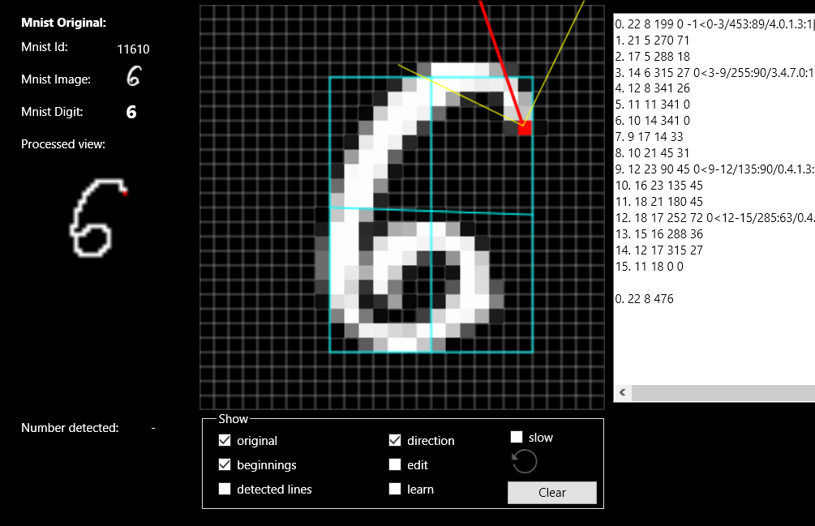
The number 6 can be recognized in several ways - in fact, it consists of several segments connected together always at a positive angle, either from a few segments forming a circle at the bottom, or from one segment forming a kind of a snail, in this case, outlining 476 degrees from beginning at the top to end at the bottom.
Such a method also has an additional advantage, it does not matter if the image is rotated by practically any angle, the thickness of the line does not matter, the size of the image or its position, i.e. everything that has a very negative influence on deep learning methods.
After all, the same sign drawn at a 45-degree angle has all the parameters described above the same.
An attentive reader will probably catch it right away, but what about the numbers 6 and 9? - Well, up to a certain angle, the number 6 is a six, and up to a certain angle it is a nine.
See the video attached, how great are the recognition problems of standard deep learning methods when you write the numbers at an angle. Remember also that the MNIST character set is already specially prepared, the characters are properly calibrated, centered, always at the same resolution of 28x28 and so on.
At this point, more efficient programmers will probably pay attention to one big problem.
The human brain simply sees the whole picture, the whole picture, lines, circles - it's simple, but the computer sees in one moment actually only one point, one of these 784 points, so how to program it, how to detect these lines? An additional problem is that some digits are written in bold, so when we see one point and check next to it there are also painted dots everywhere, how do we know in which direction the line is?

(this is how the computer sees the line)
We can use two techniques for characters:
1. simple slimming until we get a line of point thickness (the point may be a pixel, but it may also be 4 pixels, depending on needs)
2. The "fast injection method" - we imagine that we need to paint a given number with a colour (such a fill function) we let the paint in one point and look where it can spread, but as if it is under pressure, so e.g. in number 8 at the crossroads it does not spill on all sides but flies to the opposite side of the "crossroads" and flies further.

After slimming down, when we have one line, we easily extract straight, curves, angles and remember this.
I devised the method myself over 20 years ago, before writing this article I decided to write a simple programm to see if I was right. After a few days I received a program, not perfect because I don't make a commercial program, but enough to confirm that it works and has character detection over 97%, and probably if I worked for a few more days I would reach 99%.
On the other hand, it can be said that the methods described everywhere on the Internet those using neural networks do with the same detectability, so why do it differently? - Yes and no - this method does not require teaching, super computers, it does not have to be a set of only 10 characters, there can be any number of them, there does not have to be 28x28 characters because they can be in 450x725, and actually each character can be in any, each time a different format, the characters can be rotated. Adding more characters does not need to teach the network again, there is no problem that such an algorithm can recognize additional characters printed in almost any font available on the computer, of course without the need for any additional teaching.
Some people will probably write me right away that it's really just about showing on MNIST how to teach neural networks, but I can't agree with that, it really doesn't make sense. After all, we don't learn how to drive a nail with house demolition ball during technical classes.
Leave those signs alone because there is no point in using such methods.
Blow out all those thick books about Deep Learning, leave this great tool in the clouds, sit down and think about better and better algorithms by yourself, such an abecaddad of a programmer.
I was forced to write this article because while working on our strong Artificial Intelligence project SaraAI.com I am constantly being flooded with questions about what deep learning methods I use, what NLP methods, and so on. - And when I answer that I'm not directly using practically any known methods, I see only surprise and doubt on the faces of my interlocutors, so I wanted to show that we don't always have to follow the generally accepted line of solving programming problems, we can do something completely different and get much better results.
To the article I also recommend the "proof of concept" video: https://youtu.be/do9PM2PtW0M
A comment:
"Get rid of all those fat books about Deep Learning." - after these words, I hope you already know that the article is specially written in a very provocative style, because what if not emotions lead to an intensified discussion :-) (do not throw away these books!)
I don't mean to abandon Deep Learning, but to pay attention to using these methods where it is optimal. In addition, I think that the data you throw into learning should be pre-prepared as our brain does.
Although our brain receives an image from the eye made up of pixels (photons), before comparing it with a memory pattern, it processes it and prepares it in the visual cortex in V1-V5 areas - let's do the same.
Note that if you read more, it's not about the MNIST character set at all, in this method, I can add any number of characters including all Chinese and it will not change the recognition - see on the video how I add to the digits 2 and 3 Roman numerals II and III, which is completely irrelevant in such a method (I add once and they are recognized as 2 and 3 Arabic), and it is of paramount importance for methods based on neural networks.
Consider this method as a basic ABC, which, while developing, can be easily used for face recognition, or Fashion MNIST collection, as well as ImageNet.
One of the accusations is that I've been doing this program for a few days, and yet it can be done on networks in 10 minutes. OK, TensorFlow was not written in 10 minutes either. Now that I have the algorithm ready, I can add more alphabets in a few minutes.
"But there is a few-shot learning (or zero-shot learning), where we don't have to teach on 60,000 samples" - yes, but for now these methods have totally unsatisfactory results, so why, if we have here a simple and working algorithm requiring one or more samples.
"But the data augmentation is used (small angle revolutions, scaling, expansion, elongation)" - yes, but it's only the enlargement the number of samples of another thousands.
"The 97% result you're giving has no measurable value, because no one but you can test it." - The point is that now everyone can get such a result because I've given the whole method, so a good programmer will not only repeat this result but also improve it without any problem.
"Why use your algorithm and not neural networks?"
Out of curiosity I only ask, because I haven't done so much research, do you know any program/algorithm that recognizes any characters of any alphabet written and printed in any format, size, color or thickness, or on which you can perform such a test:
1 person draws any character, can be imaginary
10 other people write the same sign or a bit different
the system has to determine who wrote the wrong sign.
To make it harder, everyone has to draw the sign on the tablet in a different resolution, with a different brush thickness, different colors, different angles?
In addition, this algorithm has to work on a "calculator" without access to the network, adding more images does not require re-learning the entire database, the resources used are really negligible.
